![heartbeat[Linux-HA工程的一個組件]](/img/c/275/nBnauM3XxYTOyUTNwEDN5IDN0UTMyITNykTO0EDMwAjMwUzLxQzLzEzLt92YucmbvRWdo5Cd0FmLzE2LvoDc0RHa.jpg "heartbeat[Linux-HA工程的一個組件]")
項目簡介
 heartbeat
heartbeatHeartbeat是Linux-HA工程的一個組件,自1999年開始到現在,發布了眾多版本,是目前開源Linux-HA項目最成功的一個例子,在行業內得到了廣泛的套用,這裡分析的是2007年1月18日發布的版本2.0.8。
隨著Linux在關鍵行業套用的逐漸增多,它必將提供一些原來由IBM和SUN這樣的大型商業公司所提供的服務,這些商業公司所提供的服務都有一個關鍵特性,就是高可用集群。
原理
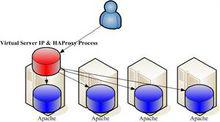
heartbeat (Linux-HA)的工作原理:heartbeat最核心的包括兩個部分,心跳監測部分和資源接管部分,心跳監測可以通過網路鏈路和串口進行,而且支持冗 余鏈路,它們之間相互傳送報文來告訴對方自己當前的狀態,如果在指定的時間內未收到對方傳送的報文,那么就認為對方失效,這時需啟動資源接管模組來接管運 行在對方主機上的資源或者服務。
高可用集群
高可用集群是指一組通過硬體和軟體連線起來的獨立計算機,它們在用戶面前表現為一個單一系統,在這樣的一組計算機系統內部的一個或者多個節點停止工作,服務會從故障節點切換到正常工作的節點上運行,不會引起服務中斷。從這個定義可以看出,集群必須檢測節點和服務何時失效,何時恢復為可用。這個任務通常由一組被稱為“心跳”的代碼完成。在Linux-HA里這個功能由一個叫做heartbeat的程式完成。
訊息通信模型
Heartbeat包括以下幾個組件:
heartbeat – 節點間通信校驗模組
CRM - 集群資源管理模組
CCM - 維護集群成員的一致性
LRM - 本地資源管理模組
StonithDaemon - 提供節點重啟服務
logd - 非阻塞的日誌記錄
apphbd - 提供應用程式級的看門狗計時器
Recovery Manager - 套用故障恢復
底層結構–包括外掛程式接口、進程間通信等
CTS – 集群測試系統,集群壓力測試
這裡主要分析的是Heartbeat的集群通信機制,所以這裡主要關注的是heartbeat模組。
heartbeat模組由以下幾個進程構成:
master進程(masterprocess)
FIFO子進程(fifochild)
read子進程(readchild)
write子進程(writechild)
在heartbeat里每一條通信通道對應於一個write子進程和一個read子進程,假設n是通信通道數,p為heartbeat模組的進程數,則p、n有以下關係:
p=2*n+2
在heartbeat里,master進程把自己的數據或者是客戶端傳送來的數據,通過IPC傳送到write子進程,write子進程把數據傳送到網路;同時read子進程從網路讀取數據,通過IPC傳送到master進程,由master進程處理或者由master進程轉發給其客戶端處理。
Heartbeat啟動的時候,由master進程來啟動FIFO子進程、write子進程和read子進程,最後再啟動client進程。
可靠訊息通信
Heartbeat通過外掛程式技術實現了集群間的串口、多播、廣播和組播通信,在配置的時候可以根據通信媒介選擇採用的通信協定,heartbeat啟動的時候檢查這些媒介是否存在,如果存在則載入相應的通信模組。這樣開發人員可以很方便地添加新的通信模組,比如添加紅外線通信模組。
對於高可用集群系統,如果集群間的通信不可靠,那么很明顯集群本身也不可靠。Heartbeat採用UDP協定和串口進行通信,它們本身是不可靠的,可靠性必須由上層套用來提供。那么怎樣保證訊息傳遞的可靠性呢?
Heartbeat通過冗餘通信通道和訊息重傳機制來保證通信的可靠性。Heartbeat檢測主通信鏈路工作狀態的同時也檢測備用通信鏈路狀態,並把這一狀態報告給系統管理員,這樣可以大大減少因為多重失效引起的集群故障不能恢復。例如,某個工作人員不小心撥下了一個備份通信鏈路,一兩個月以後主通信鏈路也失效了,系統就不能再進行通信了。通過報告備份通信鏈路的工作狀態和主通信鏈路的狀態,可以完全避免這種情況。因為這樣在主通信鏈路失效以前,就可以檢測到備份工作鏈路失效,從而在主通信鏈路失效前修復備份通信鏈路。
Heartbeat通過實現不同的通信子系統,從而避免了某一通信子系統失效而引起的通信失效。最典型的就是採用乙太網和串口相結合的通信方式。這被認為是當前的最好實踐,有幾個理由可以使我們選擇採用串口通信:
(1)IP通信子系統的失效不太可能影響到串口子系統。
(2)串口不需要複雜的外部設備和電源。
(3)串口設備簡單,在實踐中非常可靠。
(4)串口可以非常容易地專用於集群通信。
(5)串口的直連線因為偶然性掉線事件很少。
不管是採用串口還是乙太網IP協定進行通信,heartbeat都實現了一套訊息重傳協定,保證訊息包的可靠傳遞。實現訊息包重傳有兩種協定,一種是傳送者發起,另一種是接收者發起。
對於傳送者發起協定,一般情況下接收者會傳送一個訊息包的確認。傳送者維護一個計時器,並在計時器到時的時候重傳那些還沒有收到確認的訊息包。這種方法容易引起傳送者溢出,因為每一台機器的每一個訊息包都需要確認,使得要傳送的訊息包成倍增長。這種現像被稱為傳送者(或者ACK)內爆(implosion)。
對於接收者發起協定,採用這種協定通信雙方的接收者通過序列號負責進行錯誤檢測。當檢測到訊息包丟失時,接收者請求傳送者重傳訊息包。採用這種方法,如果訊息包沒有被送達任何一個接收者,那么傳送者容易因NACK溢出,因為每個接收者都會向傳送者傳送一個重傳請求,這會引起傳送者的負載過高。這種現像被稱為NACK內爆(implosion)。
Heartbeat實現的是接收者發起協定的一個變種,它採用計時器來限制過多的重傳,在計時器時間內限制接收者請求重傳訊息包的次數,這樣傳送者重傳訊息包的次數也被相應的限制了,從而嚴格的限制了NACK內爆。
實現
一般集群通信有兩類訊息包,一類是心跳訊息包,這類訊息包通告集群內節點的存活情況;另一類是控制訊息包,這類訊息包負責集群的節點和資源管理。heartbeat把心跳訊息包看成是控制訊息包的一個特例,採用相同的通信通道進行傳送,這使得協定的實現簡單化,而且很有效,並把相應的代碼限制在幾百行之內。
在heartbeat里,一切流向網路的數據都由master進程傳送到write子進程進行傳送。master進程調用send_cluster_msg()函式把訊息傳送到所有的write子進程。下面通過一些代碼片段看看heartbeat是怎么傳送訊息的。在介紹代碼之前先介紹相關的重要數據結構
Heartbeat的訊息包數據結構structha_msg{intnfields;/*訊息包數據域的個數*/intnalloc;/*己分配的記憶體塊個數*/char**names;/*訊息包數據域的名稱*/size_t*nlens;/*各個數據域稱的長度*/void**values;/*與數據域名稱對應的數據值*/size_t*vlens;/*各個數據域對應的數據值的長度*/int*types;/*訊息包的類型*/};
Heartbeat的歷史訊息佇列structmsg_xmit_hist{structha_msg*msgq[MAXMSGHIST];/*歷史訊息佇列*/seqno_tseqnos[MAXMSGHIST];/*歷史訊息序列號*/longclock_tlastrexmit[MAXMSGHIST];/*上一次重傳的時間*/intlastmsg;/*上一次重傳到的訊息序列號*/seqno_thiseq;/*最大訊息序列號*/seqno_tlowseq;/*最小訊息序列號*/seqno_tackseq;/*確認了的訊息序列號*/structnode_info*lowest_acknode;/*確認的節點*/};
代碼所屬檔案heartbeat/heartbeat.c
intsend_cluster_msg(structha_msg*msg){...pid_tourpid=getpid();...
if(ourpid==processes[0]){/*來自master進程的訊息*//*添加控制信息,包括源節點名,源節點全局標識符,序列號,代數,時間等*/if((msg=add_control_msg_fields(msg))!=NULL){/*可靠的多播訊息包傳遞*/rc=process_outbound_packet(&msghist,msg);}}else{/*來自client進程的訊息*/intffd=-1;char*smsg=NULL;
...
/*傳送到FIFO進程*/
if((smsg=msg2wirefmt_noac(msg,≤n))==NULL){...}elseif((ffd=open(FIFONAME,O_WRONLY|O_APPEND))nodename)==0);
/*把訊息轉換成字元串*/smsg=msg2wirefmt(msg,≤n);
...
if(cseq!=NULL){/*存放到歷史訊息佇列里,通過序列號記錄,如果需要,則進行重傳*/add2_xmit_hist(hist,msg,seqno);}
...
/*通過write子進程傳送到所有的網路接口上*/send_to_all_media(smsg,len);
...
returnHA_OK;}
add2_xmit_hist()函式把傳送的訊息發到一個歷史訊息佇列里去,佇列的最大長度為200。如果接收者請求重傳訊息,傳送者通過序列號在該佇列里查找要重傳的訊息,如果找到則進行重傳。下面是相關代碼。
staticvoidadd2_xmit_hist(structmsg_xmit_hist*hist,structha_msg*msg,seqno_tseq){intslot;structha_msg*slotmsg;
...
/*查找佇列里訊息存放的位置*/slot=hist->lastmsg+1;if(slot>=MAXMSGHIST){/*到達隊尾,從頭開始。在這裡實現循環佇列*/slot=0;}
hist->hiseq=seq;slotmsg=hist->msgq[slot];
/*刪除佇列中找到的位置上的舊訊息*/if(slotmsg!=NULL){hist->lowseq=hist->seqnos[slot];hist->msgq[slot]=NULL;if(!ha_is_allocated(slotmsg)){...}else{ha_msg_del(slotmsg);}}
hist->msgq[slot]=msg;hist->seqnos[slot]=seq;hist->lastrexmit[slot]=0L;hist->lastmsg=slot;
if(enable_flow_control&&live_node_count>1&&(hist->hiseq–hist->lowseq)>((MAXMSGHIST*3)/4)){/*訊息佇列長度大於告警長度,記錄日誌*/...}if(enable_flow_control&&hist->hiseq–hist->ackseq>FLOWCONTROL_LIMIT){/*訊息佇列的長度大於流控限制長度*/if(live_node_counthiseq–(FLOWCONTROL_LIMIT–1));all_clients_resume();}else{/*client進程傳送訊息過快,暫停所有的client進程*/all_clients_pause();hist_display(hist);}}
}
當傳送者收到接收者的重傳請求後,通過回調函式HBDoMsg_T_REXMIT()函式調用process_rexmit()函式進行訊息重傳。
#defineMAX_REXMIT_BATCH50/*每次最多重傳的訊息包數*/
staticvoidprocess_rexmit(structmsg_xmit_hist*hist,structha_msg*msg){constchar*cfseq;constchar*clseq;seqno_tfseq=0;seqno_tlseq=0;seqno_tthisseq;intfirstslot=hist->lastmsg–1;intrexmit_pkt_count=0;constchar*fromnodename=ha_msg_value(msg,F_ORIG);structnode_info*fromnode=NULL;
...
/*取得要重傳的訊息包的起始序列號*/if((cfseq=ha_msg_value(msg,F_FIRSTSEQ))==NULL||(clseq=ha_msg_value(msg,F_LASTSEQ))==NULL||(fseq=atoi(cfseq))lseq){/*無效序列號,記錄日誌信息*/...}
...
/*重傳丟失的訊息包*/for(thisseq=fseq;thisseqtrack.ackseq){/*該訊息包已經被確認過,可以忽略掉*/continue;}if(thisseqlowseq){/*序列號小於訊息佇列里的最小序列號,該訊息己不存在於歷史訊息佇列中*//*告知對方,不重傳該訊息*/nak_rexmit(hist,thisseq,fromnodename,“seqnotoolow”);continue;}if(thisseq>hist->hiseq){/*序列號大於訊息佇列中最大序列號*/...continue;}
for(msgslot=firstslot;!foundit&&msgslot!=(firstslot+1);--msgslot){char*smsg;longclock_tnow=time_longclock();longclock_tlast_rexmit;size_tlen;
...
/*重傳上一次重傳剩下的訊息包*/last_rexmit=hist->lastrexmit[msgslot];
if(cmp_longclock(last_rexmit,zero_longclock)!=0&&longclockto_ms(sub_longclock(now,last_rexmit))<(ACCEPT_REXMIT_REQ_MS)){gotoNextReXmit;}
/*一次不能傳送太多數據包,如果數據包太多的話,可能會引起串口溢出*/++rexm
